Chapter 4 Beginning to Understand Uncertainty
This Chapter relates to lecture 6.
In this chapter I’ll introduce core concepts around uncertainty in our results. Understanding that the results of our analysis always contain some level of uncertainty is probably the most critical concept to get our heads around as quantitative social scientists. Most of our job is not really coming up with the actual statistics, such as the correlation coefficient, or regression beta, but is more about understanding how to interpret and use those results - i.e. what they mean. And, fundamental to that is understanding their uncertainty.
Again, to reiterate the message I sent in class, many of the examples in this Chapter, and later ones, involve randomness. This means that the results here may be slightly different numerically to the results in the slides. And, if you were to run these examples yourself, you would also get slightly different results. This is nothing to worry about, because the meaning of the results does not change.
So, to start the journey, let’s grab some data.
Here, we will again use the simple three-variable set of simulated data, which represents rates of smoking, rates of cycling, and heart disease incidence.
## # A tibble: 6 × 4
## ...1 biking smoking heart.disease
## <dbl> <dbl> <dbl> <dbl>
## 1 1 30.8 10.9 11.8
## 2 2 65.1 2.22 2.85
## 3 3 1.96 17.6 17.2
## 4 4 44.8 2.80 6.82
## 5 5 69.4 16.0 4.06
## 6 6 54.4 29.3 9.55Rather than do the full ‘describe’ as I did in the last chapter, I have simply above looked at what is called the ‘head’ of the data set or the first few rows. This is because all I want to do here is double check that I have the data, and what variables are there.
Let’s calculate some simple summary statistics from this data set to build on. For example, what is the mean and median for ‘smoking’?
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.5259 8.2798 15.8146 15.4350 22.5689 29.9467Now, we know this is really simulated data, but let’s imagine for now that it was actually obtained by an organization like the Office for National Statistics in the UK, using a survey. We can presume the study was done well, and thus it is based on a true random sampling method, and we assume that the study population matches whatever target population we have in mind (remember the ‘inference gaps’ discussed in class).
What we really want to know is, how close are these statistics (i.e. the mean and median) to the true population values that we would have found if we could survey the entire target population?
Let’s begin to think about this by starting to build a table using these statistics, by going back to the slide deck…
4.1 Demonstration: Sampling from a ‘Known’ Population
Now, let’s go back one more step, and demonstrate the uncertainty inherent to sample statistics by way of example.
Let’s now assume that this sample of 498 people actually is the population we are interested in.
What this means is, we can actually draw a sample from this population of 498 and see what happens.
First, let’s present the distribution for the entire ‘population’ of 498.
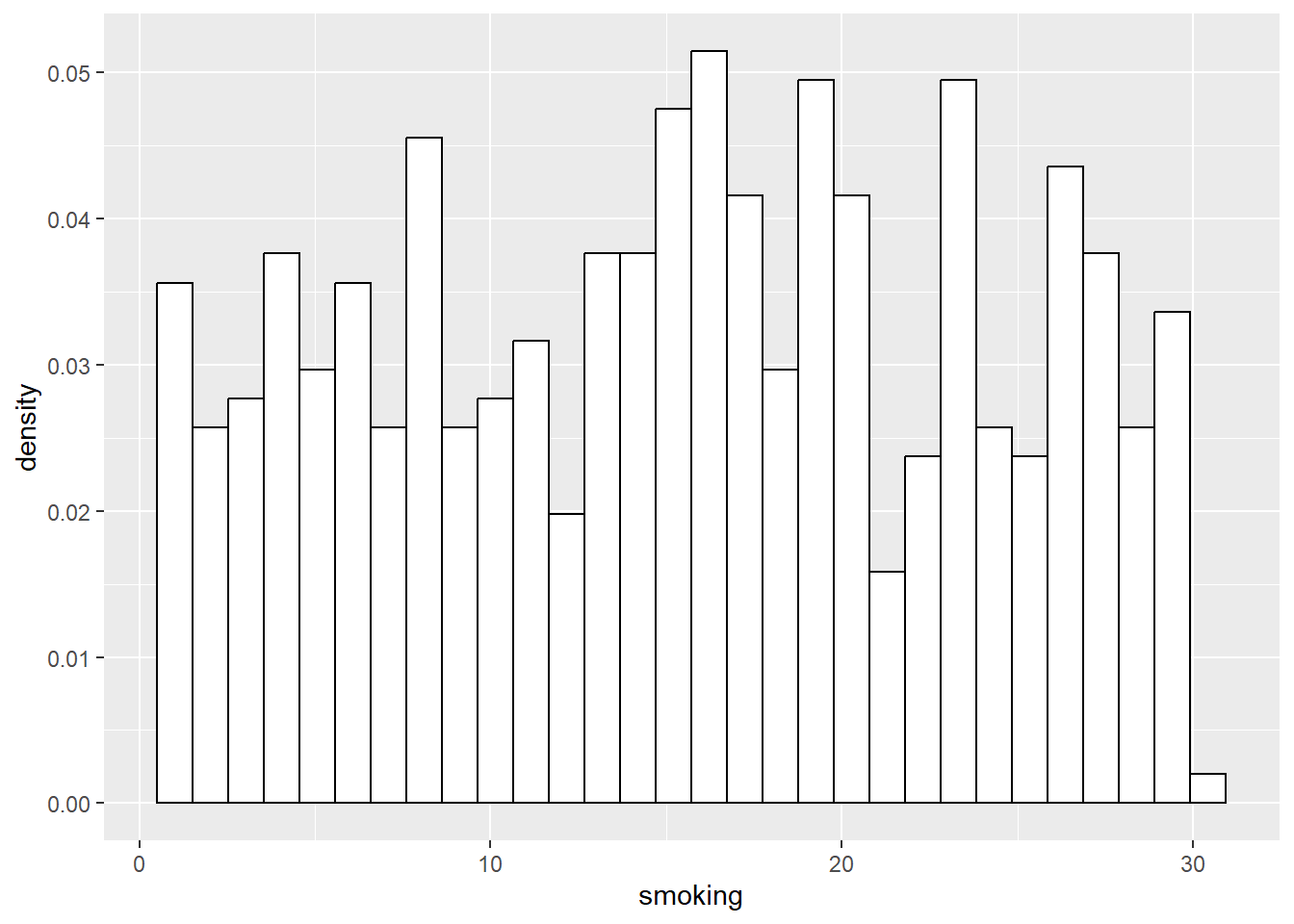
Now, let’s literally take a sample of 10 random cases from that population of 498. Here, we are sampling without replacement, and are thus essentially doing exactly what a hypothetical ‘researcher’ would do if they drew a random sample of 10 people to complete their survey, from the population of 498.
## # A tibble: 10 × 4
## ...1 biking smoking heart.disease
## <dbl> <dbl> <dbl> <dbl>
## 1 289 49.0 3.23 5.84
## 2 8 4.78 12.8 15.9
## 3 431 64.0 29.6 8.57
## 4 491 50.8 6.03 5.59
## 5 77 40.6 26.0 12.0
## 6 381 8.52 29.9 17.9
## 7 167 44.7 10.0 7.45
## 8 242 61.4 24.5 7.62
## 9 34 49.5 15.2 8.03
## 10 486 41.2 7.58 7.83Next, let’s look at the relevant statistics (median and then mean) and distribution of this sample of 10:
## [1] 14.04238## [1] 16.48825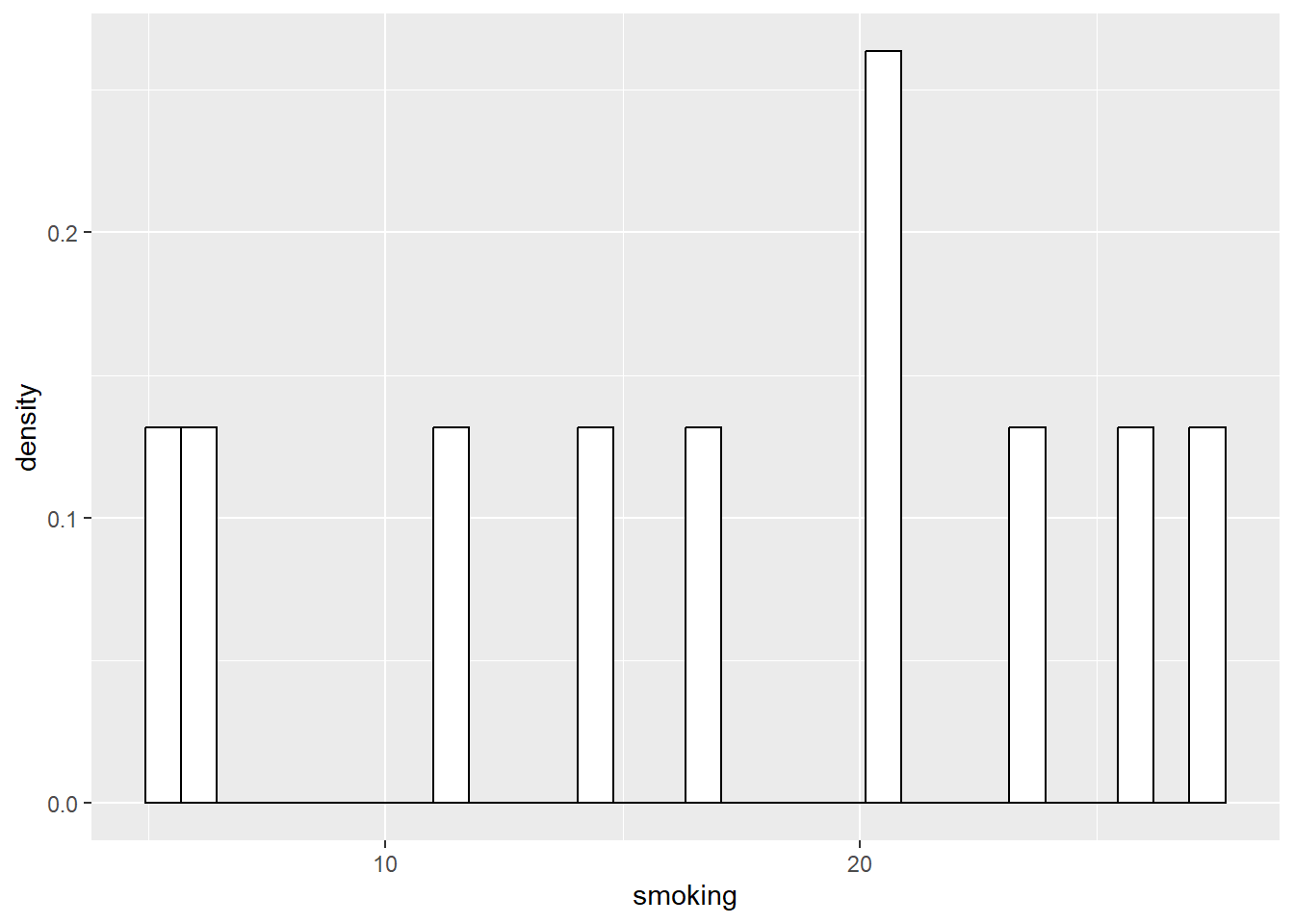
We can do the same for successively larger samples, say 50, and 200:
## # A tibble: 50 × 4
## ...1 biking smoking heart.disease
## <dbl> <dbl> <dbl> <dbl>
## 1 74 49.4 23.2 9.47
## 2 315 40.1 14.0 9.90
## 3 186 45.6 20.6 9.80
## 4 320 52.0 16.2 8.27
## 5 133 67.3 16.6 3.74
## 6 481 54.2 5.96 5.35
## 7 252 35.9 18.5 11.4
## 8 201 35.0 22.7 12.5
## 9 232 10.4 16.0 14.1
## 10 177 73.8 16.2 2.35
## # ℹ 40 more rows## [1] 15.22415## [1] 14.31424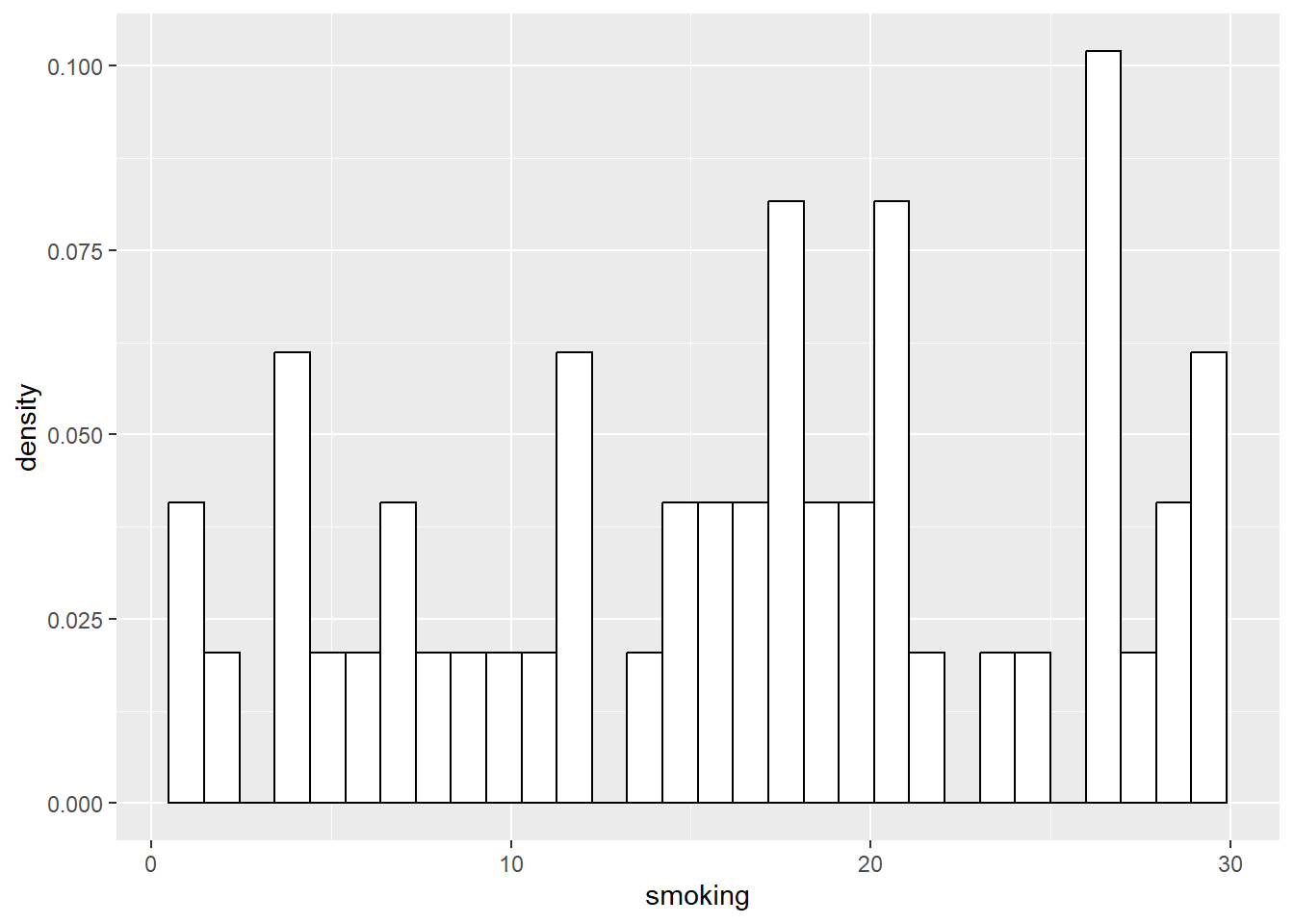
## # A tibble: 200 × 4
## ...1 biking smoking heart.disease
## <dbl> <dbl> <dbl> <dbl>
## 1 353 64.2 19.0 6.06
## 2 341 46.0 18.1 9.23
## 3 29 48.6 10.4 6.66
## 4 14 26.2 6.65 10.6
## 5 76 14.7 17.9 16.3
## 6 46 27.2 13.4 12.3
## 7 220 64.1 28.5 7.29
## 8 455 36.3 25.3 12.6
## 9 327 9.82 18.0 16.8
## 10 58 27.6 4.39 10.9
## # ℹ 190 more rows## [1] 15.24477## [1] 15.24477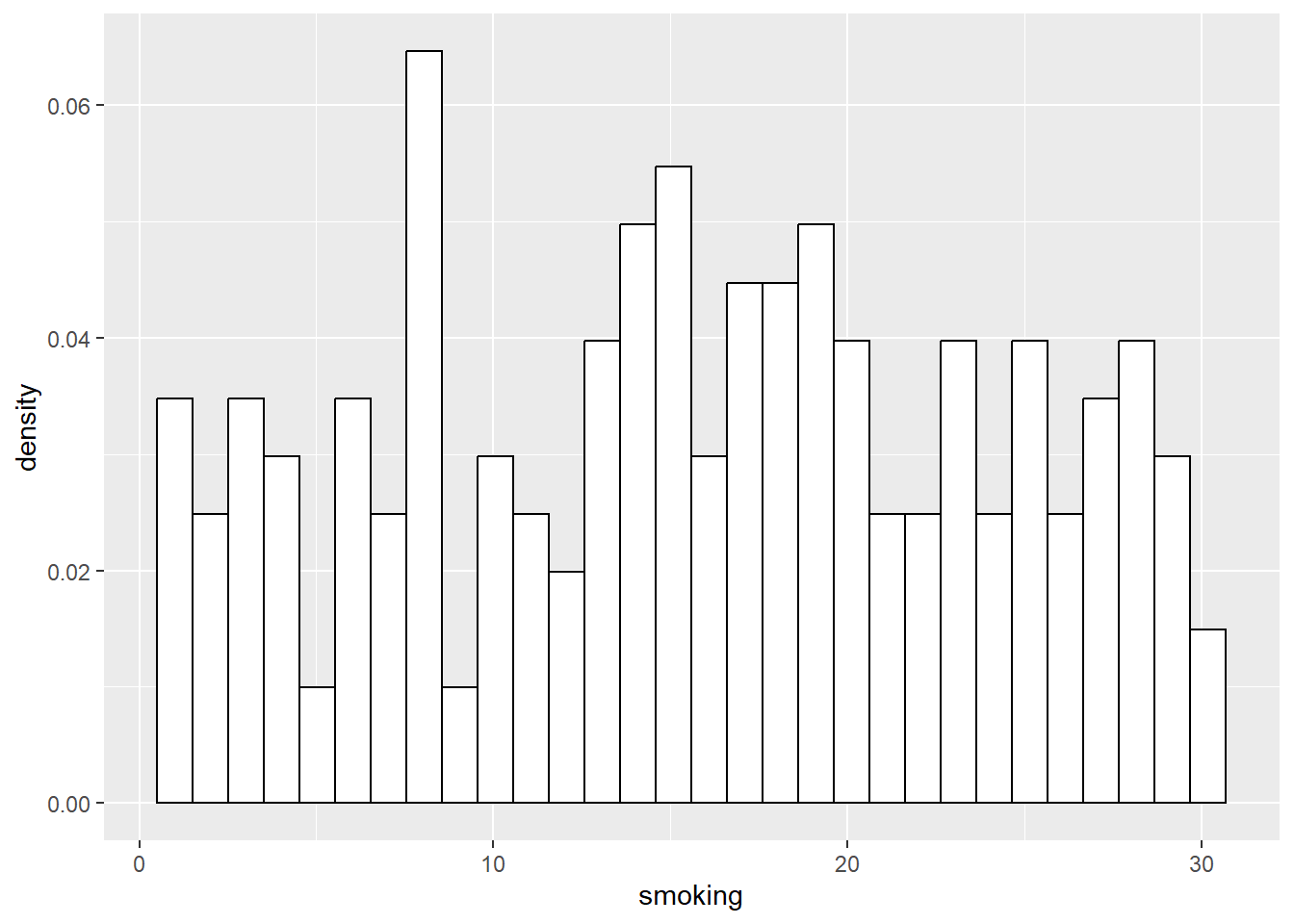
As you can see, the distributions of the smaller samples are more peaky and bumpy, because they are very sensitive to individual data points. As the sample gets larger, it starts to look more like the population right?
We can complete our table now in the slides of the sample statistics (median and mean) showing that in general, as we get closer to the population size, the statistics generally get closer too. To do so, let’s go back to the slides…